
Ещё одна китайская компания на днях удивила качественным скачком в сегменте LLM. Модели семейства Qwen 2.5-VL лидируют во многих сценариях визуального анализа, а также способны управлять смартфоном и ПК. Рассказываем о возможностях новинок.

Главные особенности
В версии 2.5-VL значительно улучшили технологии зрительного распознавания. В случае с картинками иллюстративную базу данных расширили.
Qwen идентифицирует множество категорий объектов, включая флору, фауну, мировые достопримечательности, предметы из кино- и телеиндустрии, а также коммерческие продукты. Это уже протестировали: скажем, стало удобнее загружать картинки зданий и памятников, чтобы выяснить их название и локацию.
Кроме того, точнее различаются отдельные элементы и их границы. Подробная разметка выдаётся в стандартизированном JSON-формате. Например, в изображении с несколькими пирожными ИИ точно определил видимые ингредиенты каждого.
Прокачали и OCR-сканирование. Это пригодится для извлечения текста со скриншотов и фото, ведь поддерживается немало языков, а символы могут быть перевёрнуты в любом направлении. Благодаря большому контексту — 1 млн токенов — стал возможен парсинг длинных документов. Нетрудно извлечь интересующую информацию из отчётов, книг и журналов в структурированном виде.
Вдобавок ИИ способен конвертировать тексты в HTML-формат с форматированием оригинала и принимать на вход часовые ролики. Другая интересная функция — управлением софтом на компьютерах и смартфонах по команде пользователя, подобно агенту Operator от OpenAI.
Тестировщики уже поручили Qwen заказ авиабилетов в мобильном сервисе на Android, а через ПК на Linux помощник выполнял навигацию в браузере.
Сравнение с конкурентами
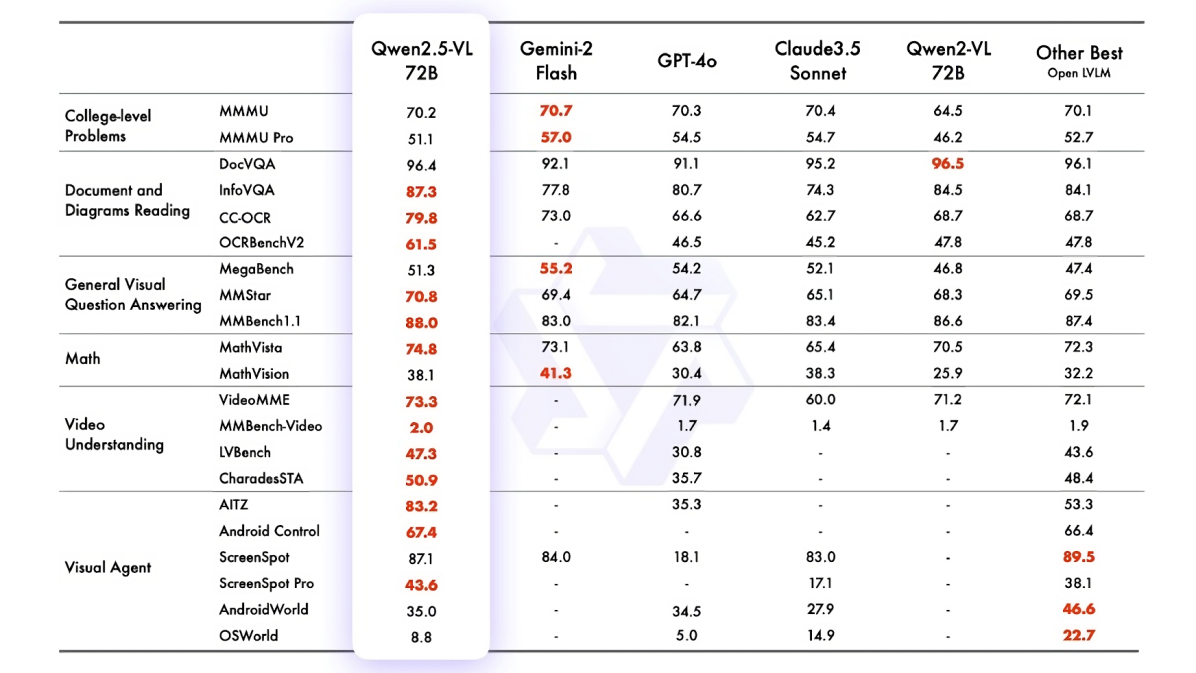
Во многих бенчмарках, оценивающих взаимодействие с визуальными данными и не только, Qwen 2.5-VL-72B демонстрирует передовые показатели. К ним относятся работа с документами и диаграммами, анализ видео и математика. Околофлагманские цифры зафиксированы и в задачах уровня колледжа.
Удобно, что модель изначально функционирует как визуальный агент без специфической настройки (fine-tuning) под задания такого рода. Отмечается превосходство над Gemini-2 Flash, GPT-4o и Claude 3.5 Sonnet в сценариях MMBench 1.1 (мультимодальные вопросы), DocVQA (скан документов с графикой и текстом) и VideoMME (понимание эмоций).
Что касается лёгких модификаций, Qwen2.5-VL-7B-Instruct оказалась лучше GPT-4o-mini в большинстве тестов. А самый компактный вариант Qwen2.5-VL-3B стал эффективнее предшественника — метрики улучшились при сниженном потреблении вычислительных ресурсов.
Опробовать Qwen 2.5-VL можно через интерфейс Hugging Face Transformers, с помощью API или в веб-версии ассистента.
